HyPOLE: Hyperproperty-Guided Multi-Agent Reinforcement Learning under Partial Observation
ICML 2026

Abstract
Formal specification is a powerful tool for guiding the learning process and provides significant advantages over reward shaping.
However, these benefits remain largely unexplored in the context of Multi-Agent Reinforcement Learning (MARL). This paper introduces HyPOLE, a novel framework for MARL under partial observability, where learning is guided by the expressive power of hyperproperties, and in particular, the temporal logic HyperLTL. We integrate Centralized Training for Decentralized Execution (CTDE) techniques with HyPOLE to synthesize decentralized policies. Our evaluation on SMAC, MessySMAC, and the WildFire benchmark demonstrates clear advantages over baselines.
Problem Statement
Given a POMDP \( \mathcal{M} \) and a HyperLTL formula \( \varphi = Q_1 \pi_1 \cdots Q_n \pi_n . \psi \), our goal is to identify a tuple of \( n \) policies \( \langle \pi_1^*, \ldots, \pi_n^* \rangle \), such that:
Example
The following example clarifies how we compute the satisfaction probability of a HyperLTL formula in our problem statement. Consider the POMDP below, where state space is agent's position, victim positions, and fire positions. Observations are partial; e.g., in state \( \langle a,f,g,c,f,i \rangle \) the agent's observation is \( \langle a \rangle \):
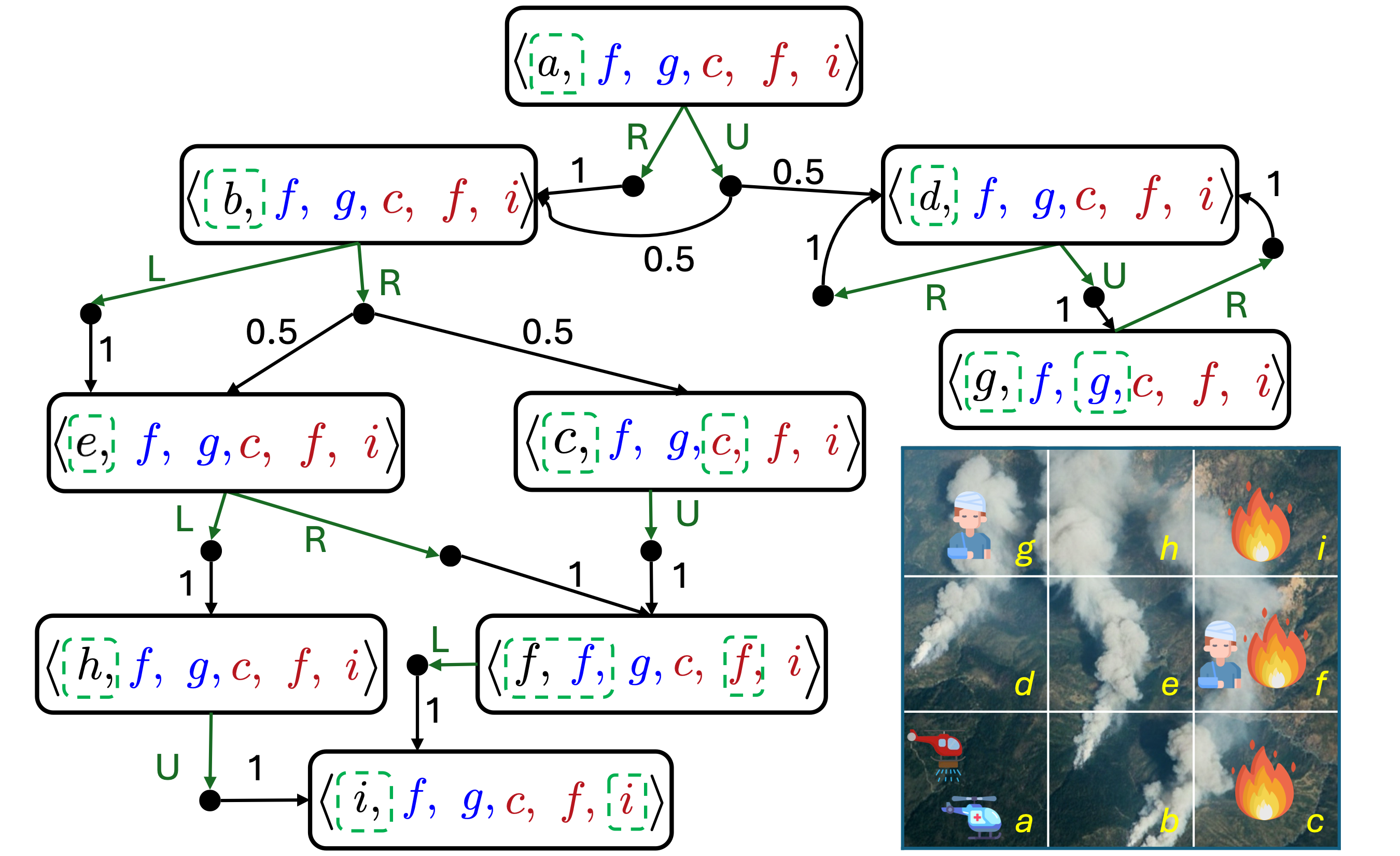
And Consider the HyperLTL formula \( \varphi_{\mathrm{exp}} \) below:
Suppose FF samples histories with policy \( \pi_1 \), \( \mathcal{H}_{\pi_1} = \{h_1^1, h_1^2\} \):
Likewise, agent Med, corresponding to \( \tau_2 \), samples histories using policy \( \pi_2 \), \( \mathcal{H}_{\pi_2} = \{h_2^1, h_2^2\} \):
The set of paths associated with \( \mathcal{H}_{\pi_i} \) is \( \mathcal{Z}_{\tau_i} = \{\arg\max_{\zeta \in \mathcal{Z}^*} \Phi(h_i^1,\zeta), \arg\max_{\zeta \in \mathcal{Z}^*} \Phi(h_i^2,\zeta)\} \), for \( i \in \{1,2\} \). We now compute the probability of satisfying \( \varphi_{\mathrm{exp}} \) using \( \mathcal{Z}_{\tau_1} \) and \( \mathcal{Z}_{\tau_2} \) as follows, for \( j \in \{1,2\} \):
Here, \( \arg\max_{\zeta \in \mathcal{Z}^*} \Phi(h_2^2,\zeta) \) serves as a witness for \( \tau_2 \) in both satisfaction relations; hence the satisfaction probability of \( \varphi_{\mathrm{exp}} \) under \( \mathcal{H}_{\tau_1} \) and \( \mathcal{H}_{\tau_2} \) is 1. However, if we replace the quantifiers in \( \varphi_{\mathrm{exp}} \) with \( \forall\forall \), the satisfaction probability drops to 0.75.
How HyPOLE works?
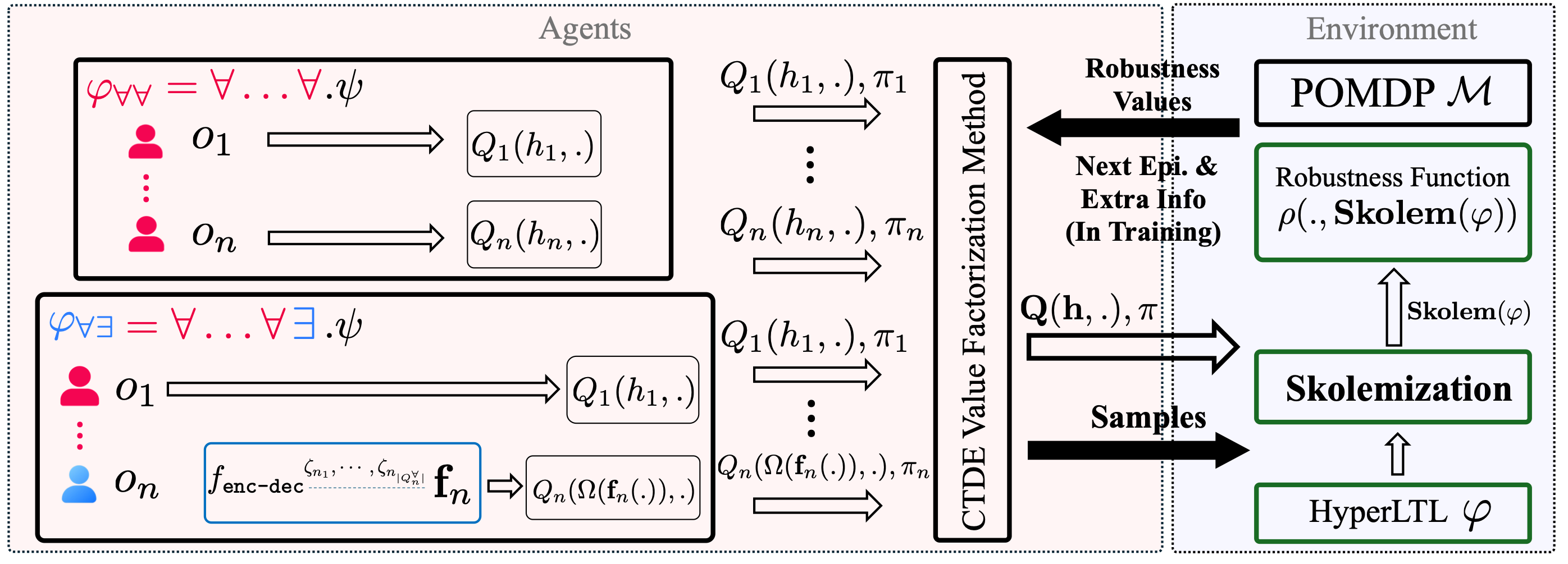
HyPOLE starts from a Skolemized HyperLTL formula and uses quantitative semantics to construct robustness-based reward signals for cooperative MARL. It synthesizes policies according to the quantifier structure: universally quantified policies use local histories, while existentially quantified policies use histories induced by the corresponding Skolem functions. During centralized training, a seq2seq model predicts traces of preceding universally quantified variables from replay-buffer samples. Finally, HyPOLE uses value-based CTDE algorithms, including VDN , QMIX , and QTRAN ,, to learn decentralized policies.
Experiments and Results
SMAC and MessySMAC

WildFire Benchmark

How does HyPOLE(\(\forall\forall\))+MARL compare with MARL using shaped rewards?
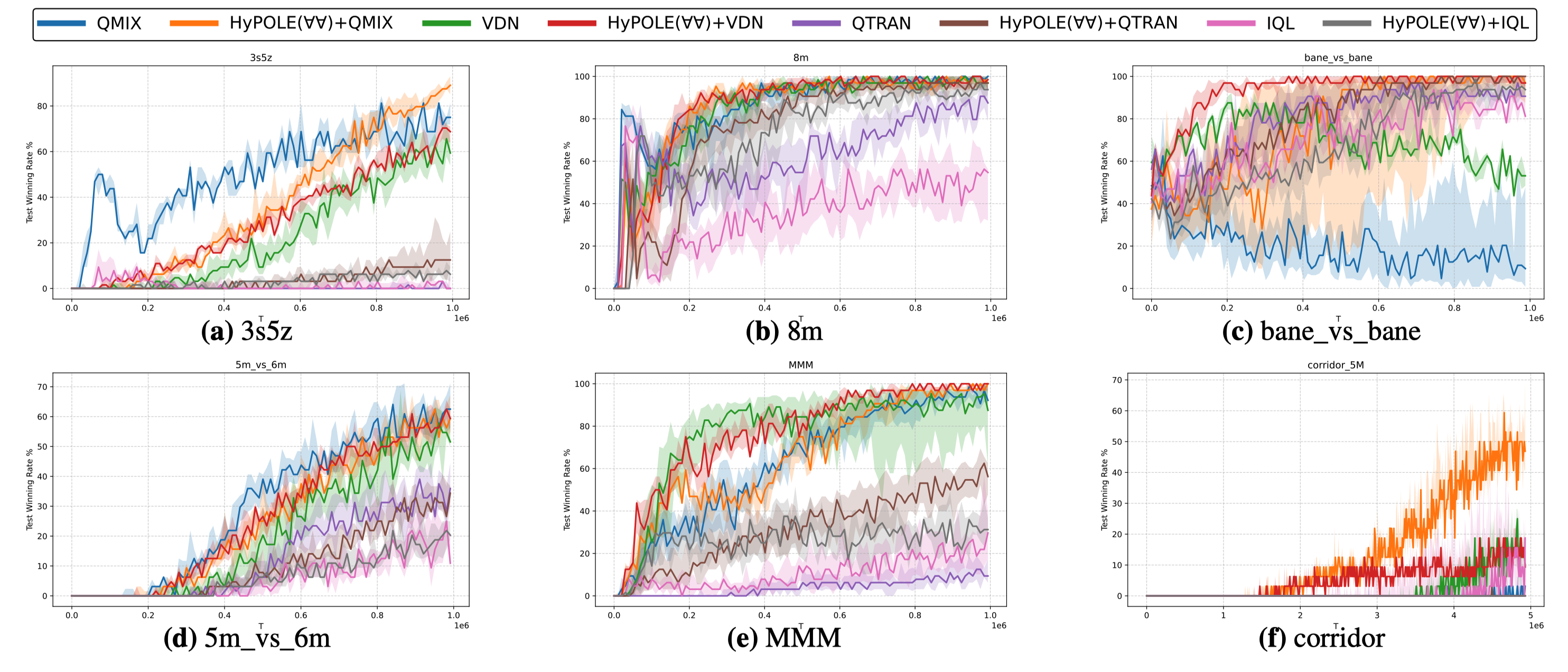
On SMAC, Under the \(\varphi_{\mathrm{focus\text{-}fire}}\) formula, HyPOLE+MARL encourages allied agents to focus fire on enemies, leading to stronger performance on 3s5z, 8m, and bane_vs_bane. On 3s5z, HyPOLE+QMIX initially underperforms vanilla QMIX, but after approximately 700K environment steps, the agents learn the focus-fire tactic and consistently outperform vanilla QMIX. On 8m, HyPOLE+MARL outperforms vanilla MARL baselines in all cases; notably, HyPOLE+IQL surpasses vanilla IQL, and HyPOLE+QTRAN outperforms vanilla QTRAN despite QTRAN being a more complex CTDE method. On bane_vs_bane, HyPOLE+QMIX and HyPOLE+VDN significantly outperform vanilla QMIX and VDN. Interestingly, On the hard corridor map, HyPOLE+QMIX reaches a median win rate of about 60%, while vanilla QMIX remains below 5%.
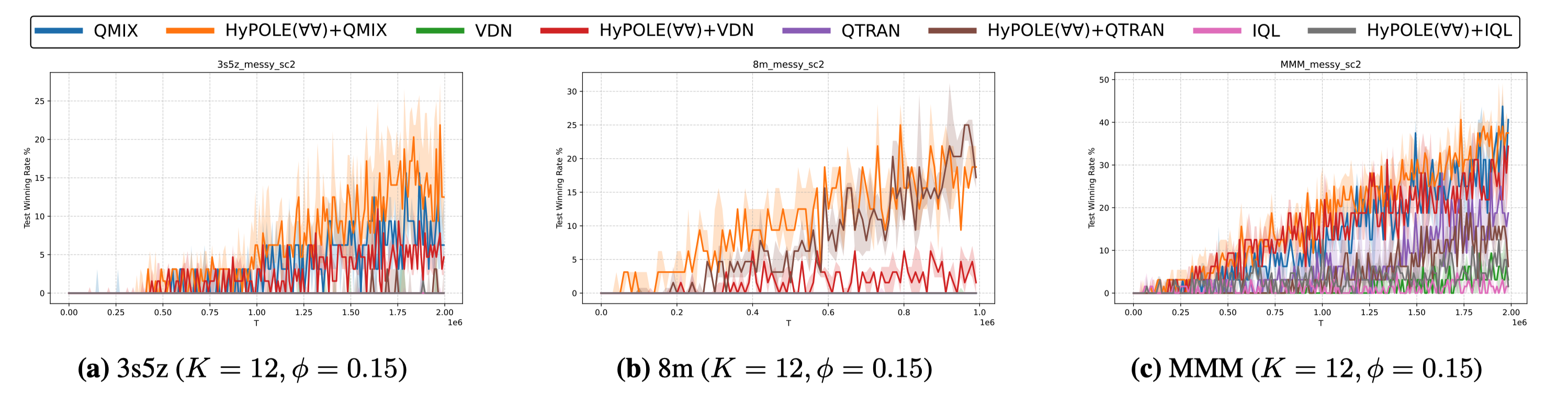
On MessySMAC, HyPOLE+MARL consistently outperforms vanilla MARL under observation and environment stochasticity. On the 3s5z map, also using \(\varphi_{\mathrm{focus\text{-}fire}}\), HyPOLE+VDN outperforms vanilla VDN, which fails to achieve any wins. On the 8m map with \(\varphi_{\mathrm{focus\text{-}fire}}\), HyPOLE+CTDE improves over vanilla CTDE in all cases; HyPOLE+QTRAN and HyPOLE+QMIX achieve win rates up to about 25%, while the vanilla baselines fail to win. HyPOLE+QMIX also performs slightly better than vanilla QMIX on the same setting. On the MMM map with \(\varphi_{\mathrm{medivac}}\), HyPOLE+VDN reaches a win rate of about 35%, substantially outperforming vanilla VDN, which remains below 10%.
What is the difference between HyPOLE(\(\forall\forall\))+MARL and HyPOLE(\(\forall\exists\))+MARL?
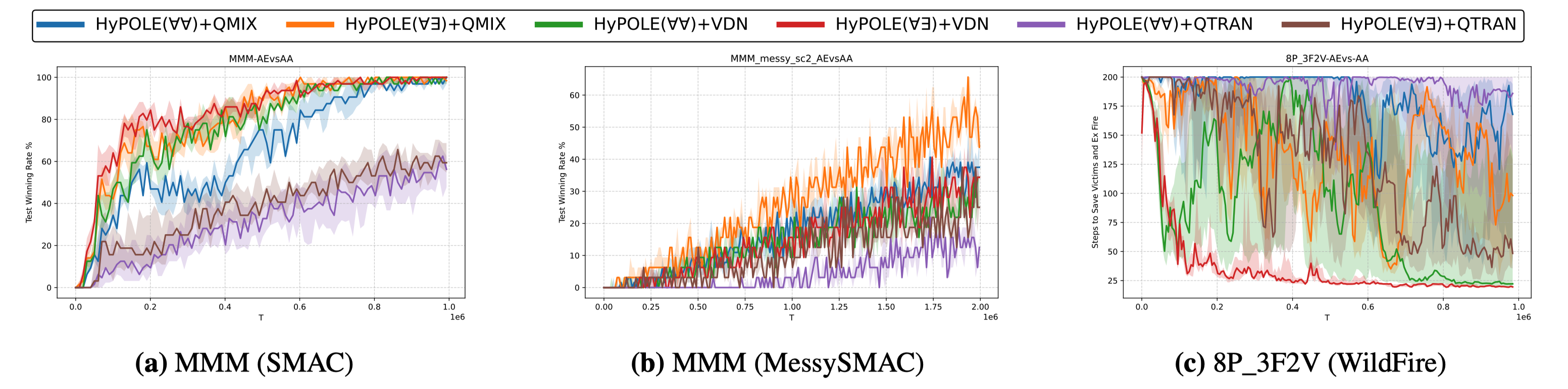
We compare \(\forall\exists\) and \(\forall\forall\) variants of HyPOLE to study how quantifier structure affects policy learning. The \(\forall\exists\) form expands the policy search space by allowing existentially quantified policies to depend on histories induced by the preceding universally quantified traces through Skolem functions. This is important in settings with inter-agent dependencies, where one agent’s behavior should adapt to the behavior or trajectory of another agent. In the MMM scenario, the Medivac agent depends on the remaining agents, and changing the Medivac quantifier from \(\forall\) to \(\exists\) enables HyPOLE to search over more expressive policies. On SMAC MMM, HyPOLE+QMIX\((\forall\exists)\) and HyPOLE+VDN\((\forall\exists)\) outperform their corresponding \(\forall\forall\) versions. On MessySMAC, HyPOLE+QMIX\((\forall\exists)\) improves over both HyPOLE+QMIX\((\forall\forall)\) and vanilla QMIX, while HyPOLE+QTRAN\((\forall\exists)\) improves the performance of HyPOLE over its \(\forall\forall\) counterpart. For the WildFire 8P_3F2V scenario, the \(\forall\exists\) version helps HyPOLE achieve better results, with HyPOLE+VDN\((\forall\exists)\) converging faster and performing substantially better than HyPOLE+VDN\((\forall\forall)\).
How can we encode tactics using HyPOLE?
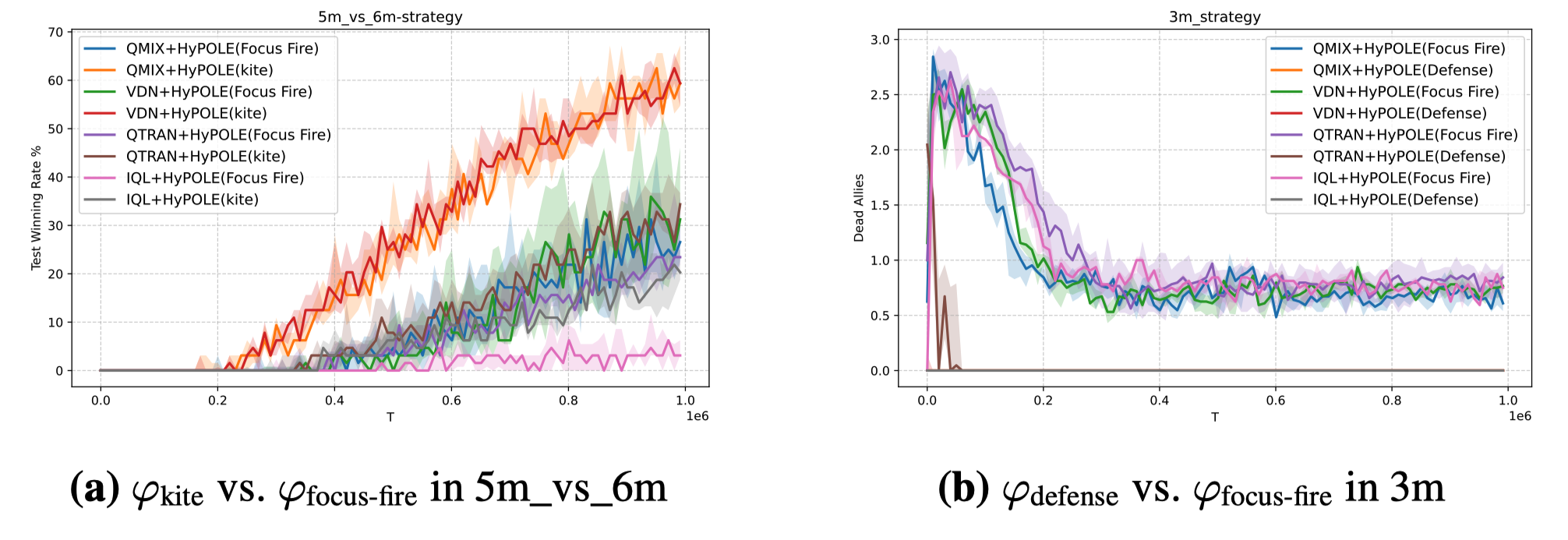
HyPOLE can encode different tactics as HyperLTL formulas and learn policies that maximize their satisfaction. In the 5m_vs_6m scenario, the \(\varphi_{\mathrm{kite}}\) formula consistently achieves higher win rates than the focus-fire formula \(\varphi_{\mathrm{focus\text{-}fire}}\), showing that kiting is a more effective tactic in this setting. On the 3m map, HyPOLE encodes a defensive tactic using \(\varphi_{\mathrm{defense}}\), which encourages allied agents to retreat from enemies and avoid casualties. The results show that HyPOLE is not limited to a single reward design, but can express different tactical behaviors through HyperLTL specifications. Overall, these experiments demonstrate that diverse tactics can be encoded in HyperLTL and compiled into effective policies via HyPOLE.
Video Demos
Corridor Demo
QMIX + HyPOLE
QMIX
MMM Demo
HyPOLE using \(\varphi_{\text{medivac}}\)
3M Demo
HyPOLE using \(\varphi_{\text{defensive}}\)
HyPOLE using \(\varphi_{\text{bad}}\)
BibTeX
@inproceedings{
hypole2026,
title={Hy{POLE}: Hyperproperty-Guided Multi-Agent Reinforcement Learning under Partial Observation},
author={Arshia Rafieioskouei and Tzu-Han Hsu and Matthew Lucas and Borzoo Bonakdarpour},
booktitle={Forty-third International Conference on Machine Learning},
year={2026},
url={https://openreview.net/forum?id=EVoPYB6ss3}
}